科学研究
科研动态
推理跟机械人,哪一个才是英伟达「AI工场」的增
作者:admin日期:2025/03/22 浏览:
 雷峰网(大众号:雷峰网)新闻,北京时光3月19日清晨,英伟达公司开创人兼CEO黄仁勋在GTC集会上宣布主题报告。DeepSeek爆火后,英伟达被推优势口浪尖,对AI开展能否会带来更年夜数目级的算力需要,市场生出隐忧。报告终场,黄仁勋便做出答复:“全天下都错了,Scaling law有更强的韧性,当初的盘算量是客岁同期的100倍。”推理让AI具有“头脑链”,模子呼应需要时会对成绩停止拆解,而不是直接给出谜底,对每个步调停止推理势必让发生的Token数目增添。模子变得愈加庞杂,为了保障原有的推理速率以及呼应才能,便对算力提出了更高的请求。Token是AI的基础单位,推理模子实质上是一座出产Token的工场,进步Token的出产速率就是进步工场的出产效力,效力越高,好处越年夜,算力要做的就是摸索出产效力的界限。
雷峰网(大众号:雷峰网)新闻,北京时光3月19日清晨,英伟达公司开创人兼CEO黄仁勋在GTC集会上宣布主题报告。DeepSeek爆火后,英伟达被推优势口浪尖,对AI开展能否会带来更年夜数目级的算力需要,市场生出隐忧。报告终场,黄仁勋便做出答复:“全天下都错了,Scaling law有更强的韧性,当初的盘算量是客岁同期的100倍。”推理让AI具有“头脑链”,模子呼应需要时会对成绩停止拆解,而不是直接给出谜底,对每个步调停止推理势必让发生的Token数目增添。模子变得愈加庞杂,为了保障原有的推理速率以及呼应才能,便对算力提出了更高的请求。Token是AI的基础单位,推理模子实质上是一座出产Token的工场,进步Token的出产速率就是进步工场的出产效力,效力越高,好处越年夜,算力要做的就是摸索出产效力的界限。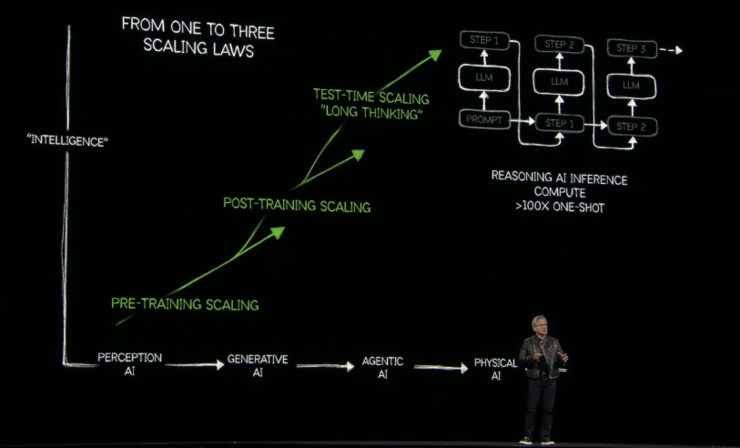 而具有自立推理才能的Agentic AI开展趋向之下,势必动员物理AI的开展。GTC集会上,英伟达带来Blackwell Ultra、推理体系Dynamo、Blackwell NVLink 72、下一代AI芯片Rubin等全新宣布,用机能回应需要。AI芯片将「年更」,Rubin机能达Hopper「900倍」AI的开展让数据核心的资源付出一直攀升,数据表现,2028年纪据核心资源付出将到达1万亿美元,黄仁勋称:“这此中的年夜局部增加可能还会减速。”资源付出增添、红利才能晋升,带来的是英伟达在数据核心范畴的营收增添。
而具有自立推理才能的Agentic AI开展趋向之下,势必动员物理AI的开展。GTC集会上,英伟达带来Blackwell Ultra、推理体系Dynamo、Blackwell NVLink 72、下一代AI芯片Rubin等全新宣布,用机能回应需要。AI芯片将「年更」,Rubin机能达Hopper「900倍」AI的开展让数据核心的资源付出一直攀升,数据表现,2028年纪据核心资源付出将到达1万亿美元,黄仁勋称:“这此中的年夜局部增加可能还会减速。”资源付出增添、红利才能晋升,带来的是英伟达在数据核心范畴的营收增添。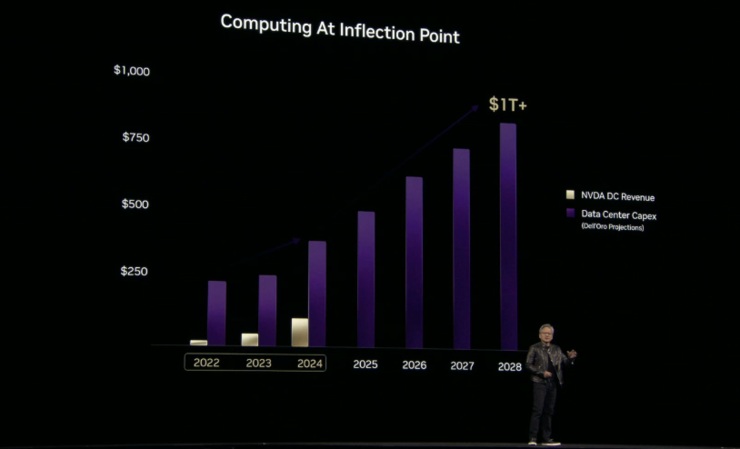 为了让盘算机成为更强的“Token天生器”,英伟达宣布新一代“最强AI芯片” Blackwell Ultra。单从硬件上看,Blackwell Ultra相较于GB200带来的最年夜进级是采取12层重叠的HBM3e内存,成为寰球首个显存到达288GB的GPU。对此,有新闻称,SK海力士将独家供给Blackwell Ultra。高效呼应推理模子,对算力、内存及带宽提出更高的请求。英伟达推出Blackwell Ultra GB300 NVL72机架级处理计划,集成72个Blackwell Ultra GPU跟36个Grace CPU,满意AI推理任务负载对算力跟内存的请求。Blackwell Ultra GB300 NVL72将于2025年下半年宣布,其机能为GB200 NVL72的1.5倍、40TB疾速闪存为前代1.5倍,14.4TB/s带宽为前代2倍。
为了让盘算机成为更强的“Token天生器”,英伟达宣布新一代“最强AI芯片” Blackwell Ultra。单从硬件上看,Blackwell Ultra相较于GB200带来的最年夜进级是采取12层重叠的HBM3e内存,成为寰球首个显存到达288GB的GPU。对此,有新闻称,SK海力士将独家供给Blackwell Ultra。高效呼应推理模子,对算力、内存及带宽提出更高的请求。英伟达推出Blackwell Ultra GB300 NVL72机架级处理计划,集成72个Blackwell Ultra GPU跟36个Grace CPU,满意AI推理任务负载对算力跟内存的请求。Blackwell Ultra GB300 NVL72将于2025年下半年宣布,其机能为GB200 NVL72的1.5倍、40TB疾速闪存为前代1.5倍,14.4TB/s带宽为前代2倍。 要更好开释硬件的算力,软硬件协同变得愈加主要,为此,英伟达推出散布式推理效劳库NVIDIA Dynamo,经由过程和谐并减速数千个GPU之间的推理通讯,为安排推理AI模子的AI工场最年夜化其token收益。在GPU数目雷同的情形下,Dynamo能够实现Hopper平台上运转Llama模子的AI工场机能跟收益翻倍,在由GB200 NVL72机架构成的集群上运转DeepSeek-R1模子时,Dynamo的智能推理优化能将每个GPU天生的Token数目进步30倍以上,并让Blackwell的机能相较于Hopper晋升了25倍。黄仁勋表皇冠真人官方网站现,Dynamo将完整开源并支撑PyTorch、SGLang、NVIDIA TensorRT-LLM跟vLLM,使企业、始创公司跟研讨职员可能开辟跟优化在分别推理时安排AI模子的方式。
要更好开释硬件的算力,软硬件协同变得愈加主要,为此,英伟达推出散布式推理效劳库NVIDIA Dynamo,经由过程和谐并减速数千个GPU之间的推理通讯,为安排推理AI模子的AI工场最年夜化其token收益。在GPU数目雷同的情形下,Dynamo能够实现Hopper平台上运转Llama模子的AI工场机能跟收益翻倍,在由GB200 NVL72机架构成的集群上运转DeepSeek-R1模子时,Dynamo的智能推理优化能将每个GPU天生的Token数目进步30倍以上,并让Blackwell的机能相较于Hopper晋升了25倍。黄仁勋表皇冠真人官方网站现,Dynamo将完整开源并支撑PyTorch、SGLang、NVIDIA TensorRT-LLM跟vLLM,使企业、始创公司跟研讨职员可能开辟跟优化在分别推理时安排AI模子的方式。 上一篇:中国电信智慧筑牢平安农村
下一篇:没有了
下一篇:没有了
相关文章
- 2025-03-22iQOO Neo9S Pro+ 5G手机 天猫精选仅2599元得手
- 2025-03-22腾讯最强!混元自研深度思考模子T1正式
- 2025-03-22长虹宣布新一代客餐厅Pro共享空调,引领
- 2025-03-21十年十倍增长,“千亿安踏”若何炼成?
- 2025-03-20法拉利超跑设计师操刀设计 剑指问界M9!